
volatile 关键字是 Java 语言的高级特性,但要弄清楚其工作原理,需要先弄懂 Java 内存模型。如果你之前没了解过 Java 内存模型,那可以先看看之前我写过的一篇「深入理解 Java 内存模型」一文。
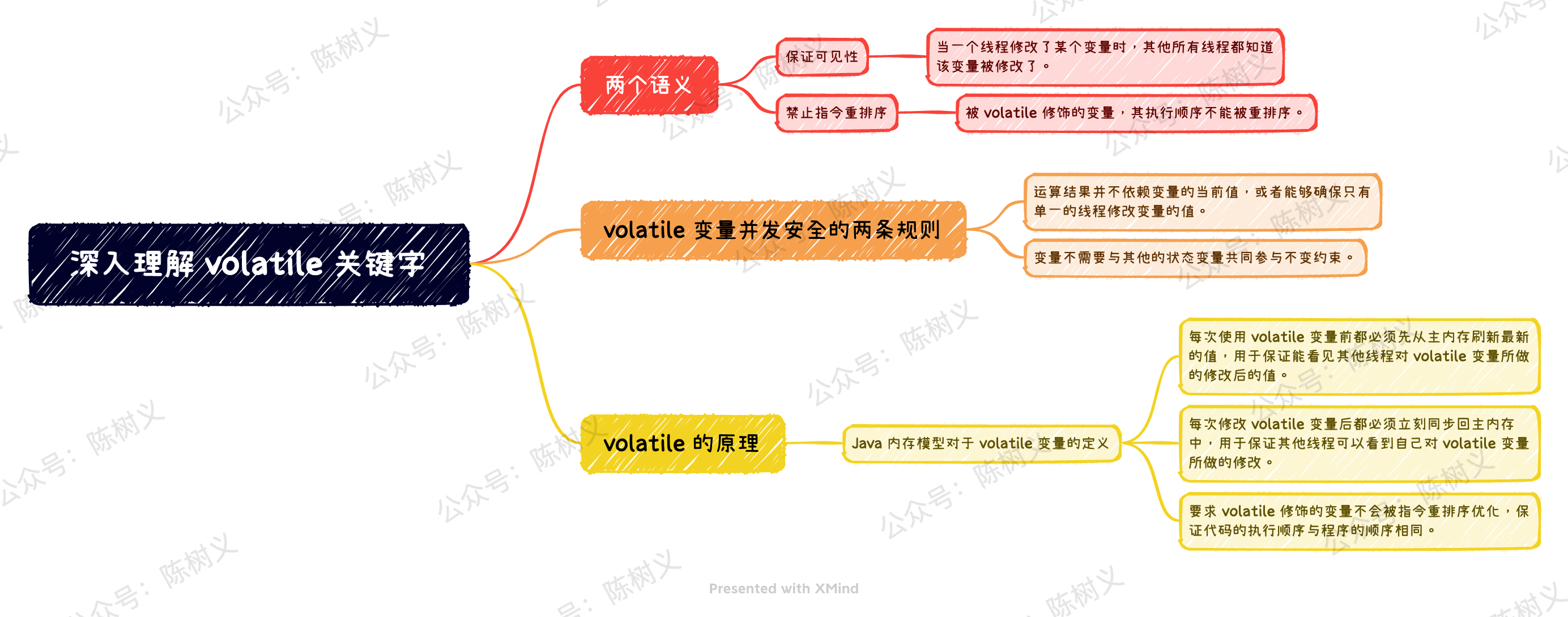
初学 volatile 关键字,我们需要弄清楚它到底意味着什么。总的来说,它有两个含义,分别是:
- 保证可见性
- 禁止指令重排序
保证可见性
保证可见性指的是:当一个线程修改了某个变量时,其他所有线程都知道该变量被修改了。 由于 volatile 可以保证可见性,因此 Java 能够保证现在在读取 volatile 变量时,线程读取到的值是准确的。但是这并不意味着对 volatile 变量的操作是线程安全的,因为有可能在读取到变量之后,又有其他线程对变量进行修改了。
为了说明这个问题,我们可以举个简单地例子。下面代码发起了 20 个线程,每个线程对 race 变量进行 1 万次自增操作。如果这段代码能够正确并发执行,那么最后输出的结果应该是 20 万。但实际上,每次输出的结果都不一样,都是一个小于 20 万的数字,为什么呢?
这是因为当线程在获取到 race 变量的值,然后对其进行自增这中间,有可能其他线程对 race 变量做了自增操作,然后写回了主内存。而当前线程再将数据写回主内存时,就发生了数据覆盖。因此,就发生了数据不一致的问题。
要使得 volatile 变量不发生并发安全问题,只需要遵守如下两条规则即可:
- 运算结果并不依赖变量的当前值,或者能够确保只有单一的线程修改变量的值。
- 变量不需要与其他的状态变量共同参与不变约束。
第一条规则比较好理解,例如上面例子的 race 变量,其运算结果就依赖于变量的当前值,所以其并不符合第一条规则,因此就会有线程安全问题。但如果 race++ 变成了 race=1; 这样的情况,那么 race 的值就不依赖变量当前值,因此就不会有线程安全问题。
第二条规则有点晦涩难懂。其意思是说,变量不能和其他变量一起参与判断,无论其他变量是否是 volatile 类型的变量。例如 if(a && b) 这个判断就无法满足 volatile 的第二条规则,会发生线程安全问题,即使这两个变量都是 volatile 类型的变量。
关于第二条规则的描述,为啥与其他变量一起,就没法保证线程安全呢?
要解答这个问题,我们不妨假设一下各种可能的场景。
我们假设变量 a b 的初始值都是 true,并且两者都是 volatile 类型变量。
场景一:线程 A 执行 if(a && b) 判断,先判断变量 a,发现是 true,于是继续判断变量 b。发现变量 b 也是 true,于是整个表达式为 true。
场景二:线程 A 执行 if(a && b) 判断,先判断变量 a,发现是 true。此时线程 B 修改了变量 b 的值为 false。接着线程 A 继续判断变量 b 的值,发现变量 b 的值为 false。于是整体表达式的值为 false。
通过上面的例子,我们发现同样的表达式在不同的并发场景下会有不同的结果,这很明显就是线程不安全的。因为线程安全的代码,在单线程和多线程下,其结果应该是一样的。
禁止指令重排序
指令重排序,指的是硬件层面为了加快执行速度,可能会调整指令的执行顺序,从而会出现并不按代码顺序的执行情况出现。例如下面的代码里,我们初始化了 flag 变量为 false,然后再将 flag 变量置为 true。但这样的代码在并发执行的时候,有可能先将 flag 职位 true,再将 flag 变为 false,从而发生线程安全问题。
boolean flag = false;
flag = true;
我们说 volatile 变量禁止指令重排序,其实就是指被 volatile 修饰的变量,其执行顺序不能被重排序。 禁止重排序的实现,是使用了一个叫「内存屏障」的东西。简单地说,内存屏障的作用就是指令重排序时,不能把后面的指令重排序到内存屏障之前的位置。
可见性的来源
我们前面说过:volatile 修饰的变量,当其被修改之后,其他变量就能立即获取到其变化。但这个可见性的来源是哪里呢?为什么其能够实现这样的可见性呢?其实 volatile 的这些功能来源于 Java 内存模型中对 volatile 变量定义的特殊规则。
假定 T 表示一个线程,V 和 W 分别表示两个 volatile 型变量。在 Java 内存模型中规定在进行 read、load、use、assign、store 和 write 操作时需要满足如下规则:
- 只有当线程 T 对变量 V 执行的前一个动作是 load 的时候,线程 T 才能对变量 V 执行 use 动作。并且,只有当线程 T 对变量 V 执行的后一个动作是 use 的时候,线程 T 才能对变量 V 执行 load 动作。
- 只有当线程 T 对变量 V 执行的前一个动作是 assign 的时候,线程 T 才能对变量 V 执行 store 动作;并且,只有当线程 T 对变量V执行的后一个动作是 store 的时候,线程 T 才能对变量 V 执行 assign 动作。
- 假定动作 A 是线程 T 对变量 V 实施的 use 或 assign 动作,假定动作 F 是和动作 A 相关联的 load 或 store 动作,假定动作 P 是和动作 F 相应的对变量 V 的 read 或 write 动作。类似的,假定动作 B 是线程 T 对变量 W 实施的 use 或 assign 动作,假定动作 G 是和动作 B 相关联的 load 或 store 动作,假定动作 Q 是和动作 G 相应的对变量 W 的 read 或 write 动作。如果 A 先于 B,那么 P 先于 Q。
上面三条规则有点复杂,我们来一条条讲解下。
首先,我们来看看第一条规则。
只有当线程 T 对变量 V 执行的前一个动作是 load 的时候,线程 T 才能对变量 V 执行 use 动作。
load 动作,指的是把从主内存得到的变量值,放入到工作内存的变量副本。use 动作,指的是将工作内存的一个变量值,传递给执行引擎。那么这句话合起来的意思可以理解为:要使用变量 V 之前,必须去主内存读取变量 V。
并且,只有当线程 T 对变量 V 执行的后一个动作是 use 的时候,线程 T 才能对变量 V 执行 load 动作。
这句的意思可以理解为:要去读取主内存的变量值放入工作内存的变量副本,那就必须使用它。
总的来说,这条规则的意思是:线程对变量 V 的 use 动作,必须与 read、load 动作连在一起,即 read -> load -> use 必须一起出现。这条规则要求在工作内存中,每次使用 V 前都必须先从主内存刷新最新的值,用于保证能看见其他线程对变量V所做的修改后的值。
我们继续看第二条规则。
只有当线程 T 对变量 V 执行的前一个动作是 assign 的时候,线程 T 才能对变量 V 执行 store 动作。
assign 动作,指的是将执行引擎的值赋值给工作内存的变量。store 动作,指的是将工作内存的一个变量传送到主内存,方便后续写回主内存。那么这句话合起来的意思可以理解为:要讲工作内存的变量写回主内存,那么必须是工作内存的变量收到执行引擎的赋值。
并且,只有当线程 T 对变量 V 执行的后一个动作是 store 的时候,线程 T 才能对变量 V 执行 assign 动作。
这句话的意思可以理解为:要将执行引擎接收到的值赋给工作内存的变量,就必须把工作内存变量的值写回主内存。
总的来说,这条规则的意思是:线程对变量 V 的 assign 动作,必须与 store、write 连在一起,即:assign -> store -> write 必须一起出现。这条规则要求在工作内存中,每次修改 V 后都必须立刻同步回主内存中,用于保证其他线程可以看到自己对变量 V 所做的修改。
我们继续看第三条规则。
假定动作 A 是线程 T 对变量 V 实施的 use 或 assign 动作,假定动作 F 是和动作 A 相关联的 load 或 store 动作,假定动作 P 是和动作 F 相应的对变量 V 的 read 或 write 动作。
这句话意思比较简单,use 和 assign 动作分别是从工作内存传递变量给执行引擎,以及从执行引擎传递变量给工作内存。load 和 store 动作分别是从主内存载入数据到工作内存,以及从工作内存写数据到主内存。read 和 write 动作分别是将数据读取到工作内存,以及将数据写回主内存。
我们假设是一个写入到主内存动作,如果这几个组合起来,那么就是:A -> F -> P(assign -> store -> write)。
类似的,假定动作 B 是线程 T 对变量 W 实施的 use 或 assign 动作,假定动作 G 是和动作 B 相关联的 load 或 store 动作,假定动作 Q 是和动作 G 相应的对变量 W 的 read 或 write 动作。
与上面类似,如果是一个写入到主内存动作,如果这几个组合起来,那么就是:B -> G -> Q(assign -> store -> write)。
如果 A 先于 B,那么 P 先于 Q。
这个的意思是,如果 A 动作早于 B 动作发生,那么 A 动作对应的 P 动作(write 动作)就要早于 Q 动作(write 动作)。
这条规则要求 volatile 修饰的变量不会被指令重排序优化,保证代码的执行顺序与程序的顺序相同。
所以说 volatile 变量的可见性以及禁止重排序的语义,其实都来源于 Java 内存模型里对于 volatile 变量的定义。
总结
这篇文章,我们介绍了 volatile 的两个语义:
- 可见性
- 禁止重排序
可见性指的是 volatile 类型的变量,其变量值一旦被修改,其他线程就能够立刻感知到。而禁止重排序指的是被 volatile 修饰的变量,其执行顺序不能被重排序。我们在日常使用中,如果要使 volatile 变量不发生线程安全问题,只需要遵守下面两个规则即可。
- 运算结果并不依赖变量的当前值,或者能够确保只有单一的线程修改变量的值。
- 变量不需要与其他的状态变量共同参与不变约束。
最后,我们进一步探究了 volatile 可见性以及禁止重排序的来源,其实就是 Java 内存模型里对于 volatile 变量的定义。
参考资料
- 《深入理解 Java 虚拟机》
- 如何理解 “变量不需要与其他的状态变量共同参与不变约束” 一话? - 知乎